In this article, I would like to show you an end-to-end configuration for creating Gitlab CI pipelines for Terraform, using GCP as Remote Storage, step by step.
GCP Account Configuration
The account configuration can be made in many different ways. My choice is to have a project for DevOps, and a project per environment, as illustrated in the image below.
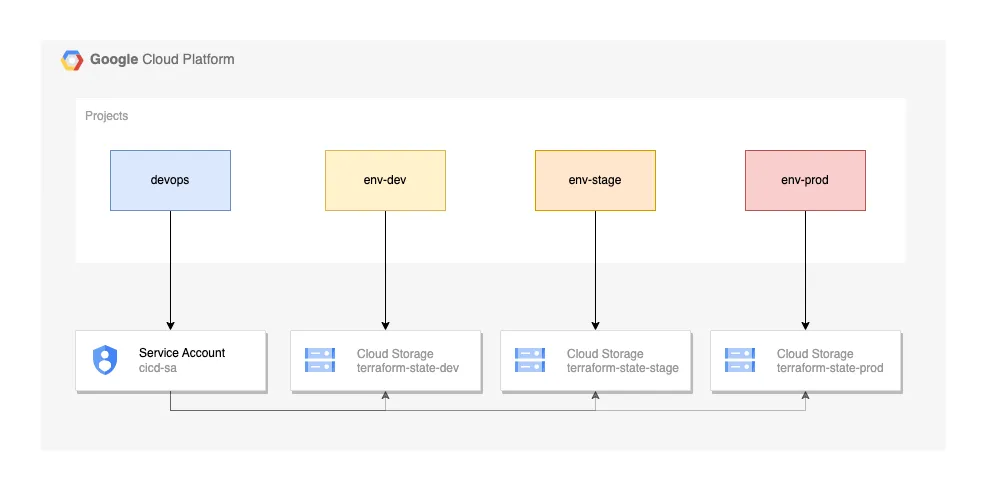
In the DevOps project, we need to configure a Service Account with Editor Permission that will be used by the pipelines to deploy the resources. To do that:
- Go to the IAM in the DevOps project, and create a Service Account.
Choose a name
Give Editor Permission and create (you can skip step 3)
Now, let’s create a key for the Service Account. Please select the service account, go to the Key section, and add a key in JSON format. Save it for we use in Gitlab CI.
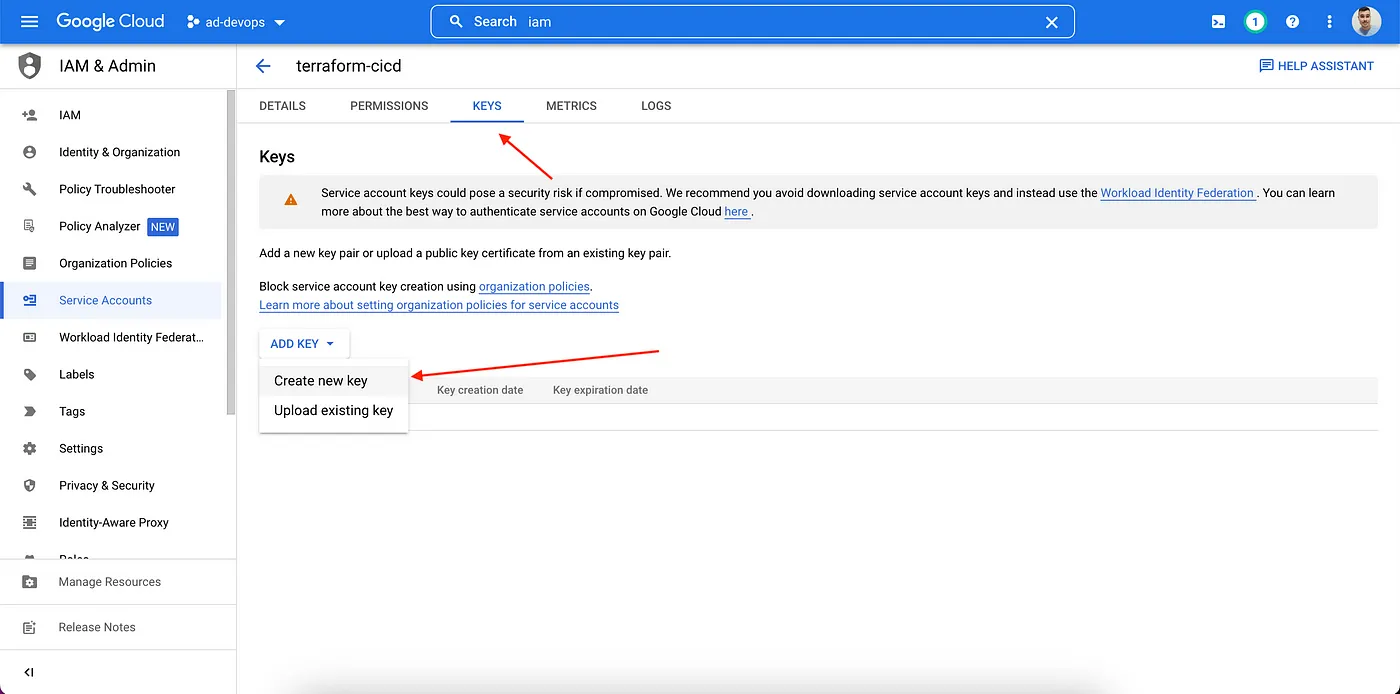
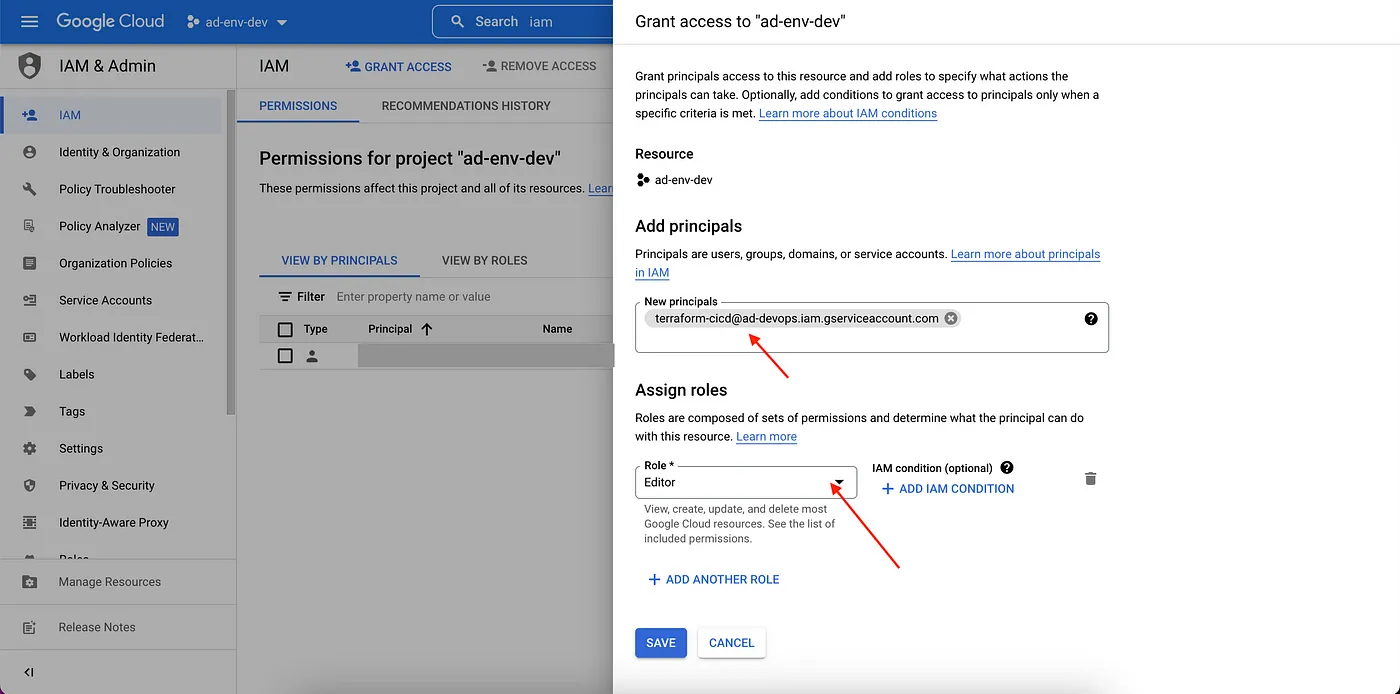
Now, we need to grant access to that service account to be able to create resources in the dev, stage, and prod projects. For this, go to each environment project, in the IAM page and click on Grant Access.

Add the email of the service account created in the DevOps project, and give Editor Permission too (repeat this process in each environment project).
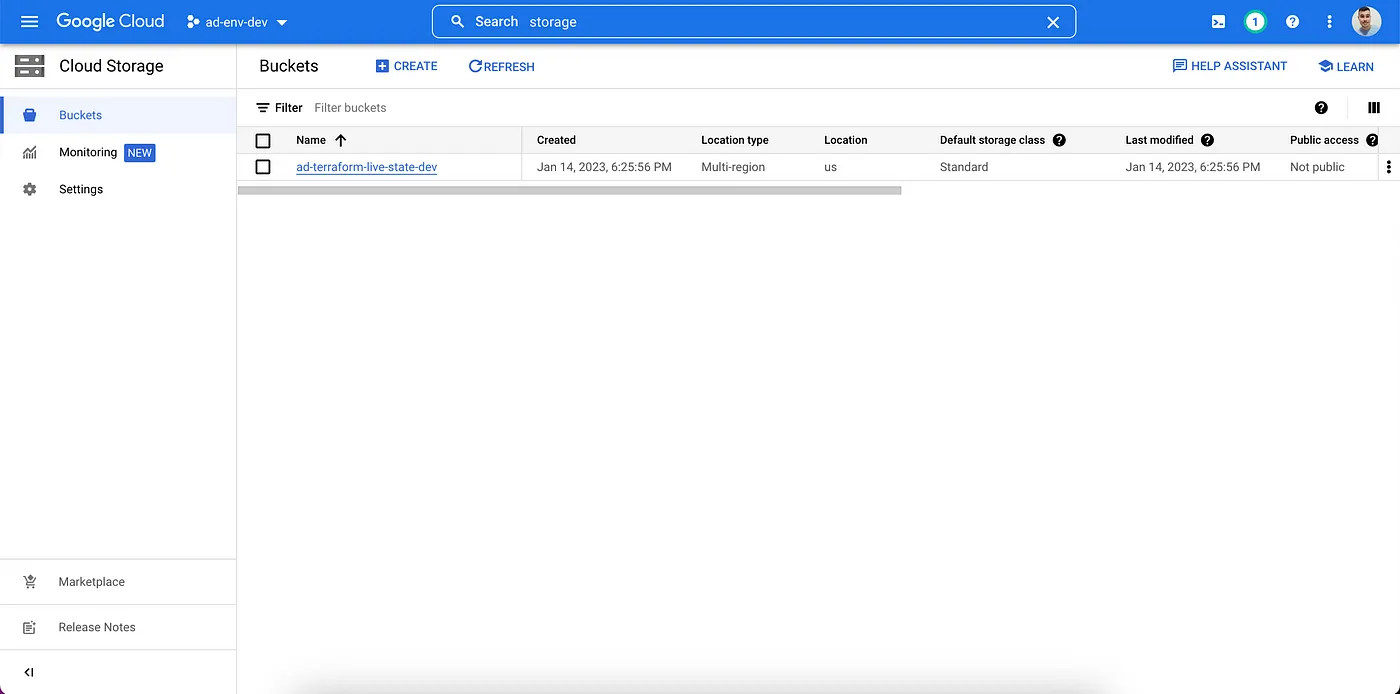
Unfortunately, differently of Terragrunt, pure Terraform code doesn’t create automatically the bucket for the remote state. So, go to each environment project and create a bucket to be used to store the remote state of each env.
Disclaimer: It’s highly recommended to enable bucket versioning.
And that’s all for GCP.
Gitlab Configuration
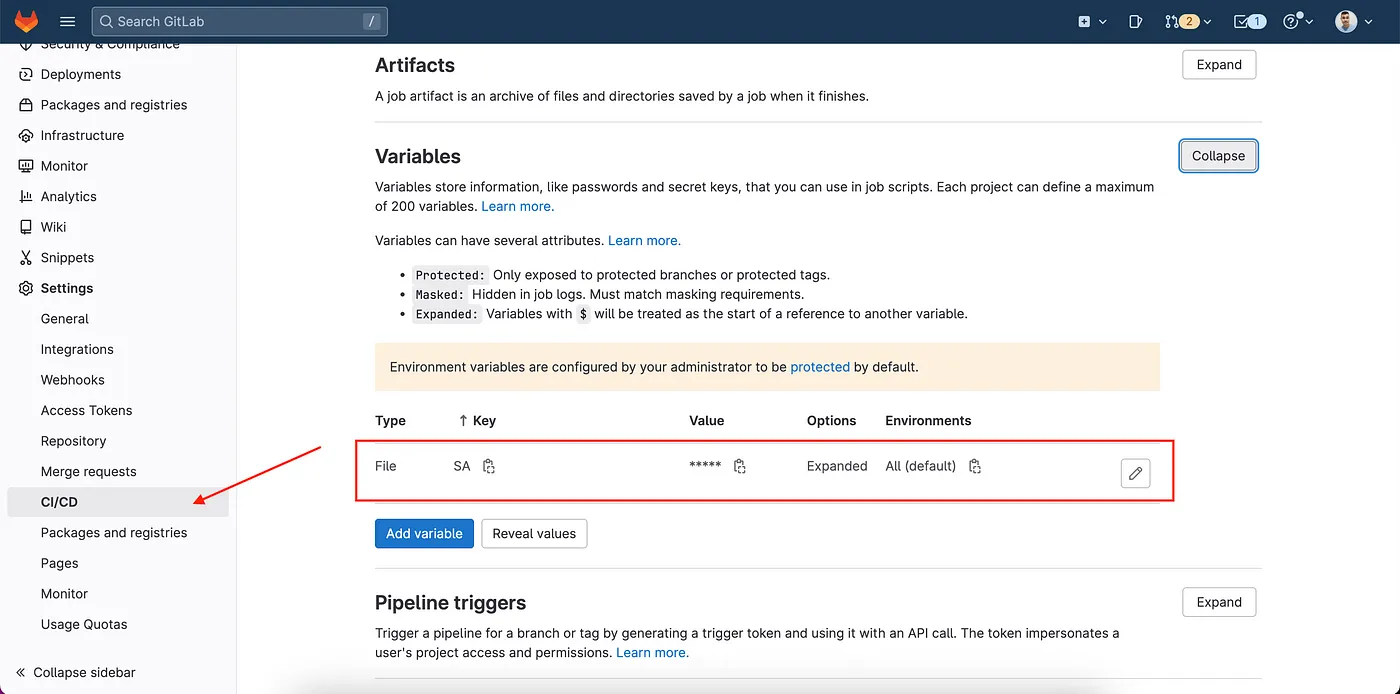
In Gitlab, we just need to configure our Service Account as a Variable.
- In your Gitlab Setting Page, in the CICD Subsection, create a variable called “SA” of File type.
- Paste the value of the SA JSON that you have downloaded in the previous steps.
Code Structure
In this example, I’m using a folder structure as below, but you can adapt it accordingly to your necessities.
terraform-infra-live/
├─ infra/
│ ├─ stage/
│ │ ├─ main.tf
│ ├─ prod/
│ │ ├─ main.tf
│ ├─ dev/
│ │ ├─ main.tf
├─ modules/
│ ├─ gcp/
│ │ ├─ gce/
│ │ ├─ firewall-rule/
│ │ ├─ gcs/
The main code contains a code like below, which you need to change in each main.tf file the values of the bucket and your project id for each environment.
terraform {
required_providers {
google = "4.10.0"
}
backend "gcs" {
bucket = "REPLACE-WITH-YOUR-BUCKET-NAME-dev"
prefix = "terraform/state"
}
}
provider "google" {
project = "REPLACE-WITH-YOUR-PROJECT-ID-dev"
region = "us"
}
locals {
project_id = "REPLACE-WITH-YOUR-PROJECT-ID-dev"
environment = "dev"
}
...
## Add your modules and the remaining code...
Pipelines
The pipelines are very simple and created for feature-based workflows
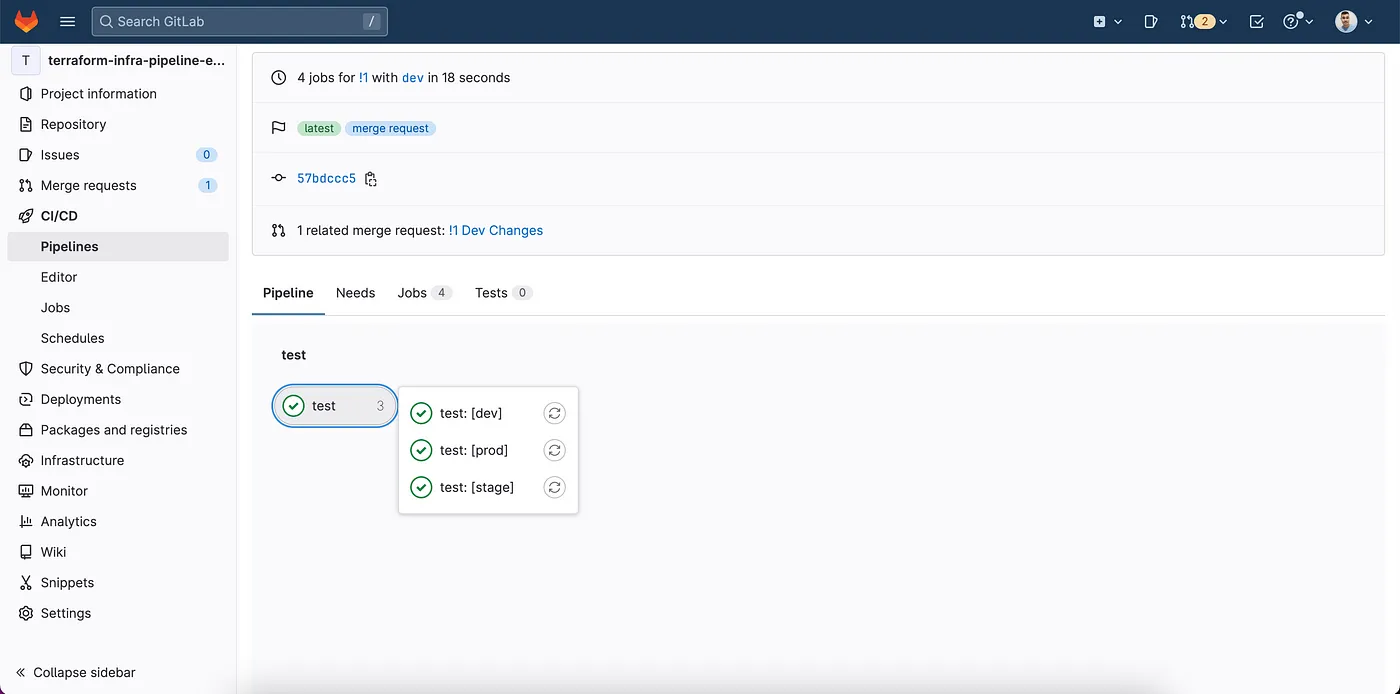
A pipeline for Merge Request, where the validations will be made.
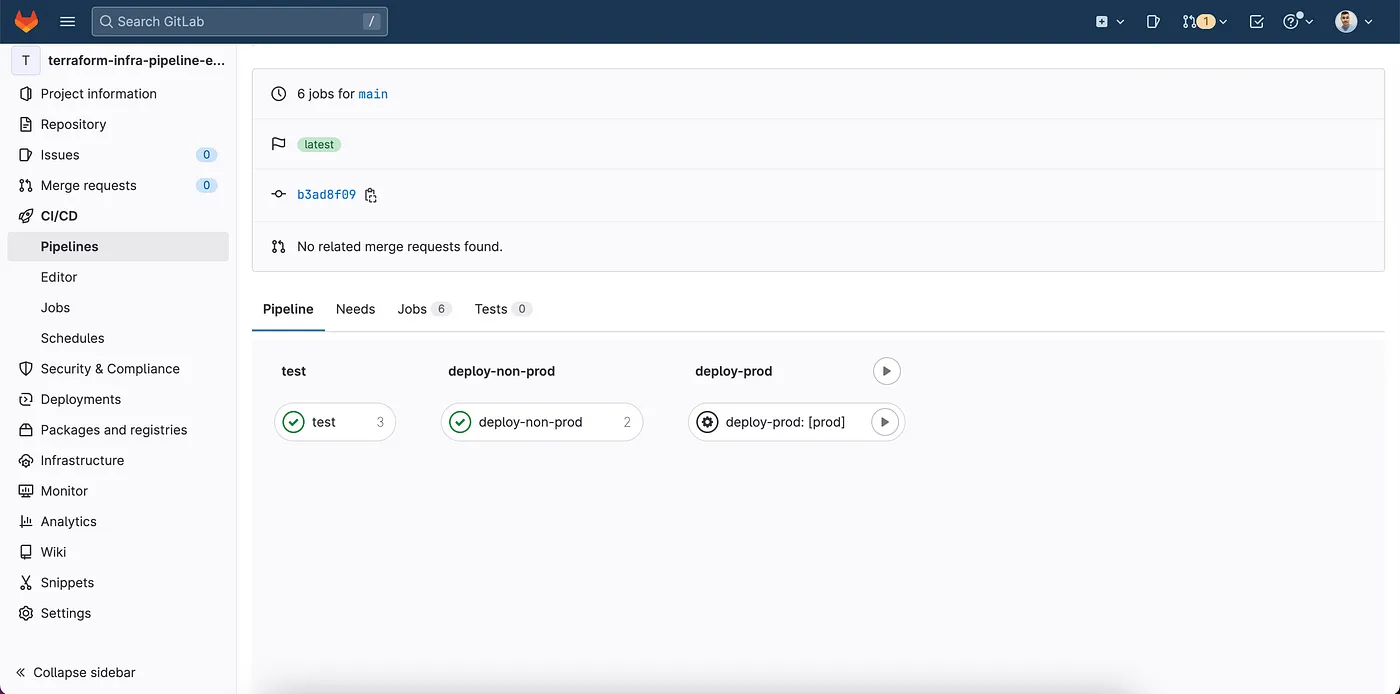
A pipeline for the main branch, where the code will be deployed automatically across each non-prod env in parallel, and the prod environment manually.
The code
image:
name: hashicorp/terraform:1.3.2
entrypoint:
- "/usr/bin/env"
- "PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin"
stages:
- test
- deploy-non-prod
- deploy-prod
before_script:
- cp $SA /tmp/credentials.json
- export GOOGLE_APPLICATION_CREDENTIALS="/tmp/credentials.json"
.deploy: &deploy
script:
- terraform init
- terraform plan -lock=false -out plan.json
- terraform apply -auto-approve plan.json
test:
stage: test
script:
- terraform fmt --recursive -check
- cd infra/$ENV_NAME
- terraform init
- terraform validate
- terraform plan -lock=false
parallel:
matrix:
- ENV_NAME: [ dev, stage, prod ]
only:
- main
- merge_requests
deploy-non-prod:
stage: deploy-non-prod
script:
- cd infra/$ENV_NAME
- !reference [.deploy, script]
parallel:
matrix:
- ENV_NAME: [ dev, stage ]
only:
- main
dependencies:
- test
deploy-prod:
stage: deploy-prod
script:
- cd infra/$ENV_NAME
- !reference [.deploy, script]
parallel:
matrix:
- ENV_NAME: [ prod ]
only:
- main
when: manual
dependencies:
- deploy-non-prod
after_script:
- rm /tmp/credentials.json
Other Considerations
As the pipeline will perform a lint check, it’s a good idea to execute a “terraform fmt -recursive” before pushing your code.
You can check the complete code example in my Github: https://github.com/andersondario/terraform-infra-gitlab-example
Support
If you find my posts helpful and would like to support me, please buy me a coffee: Anderson Dario is personal blog and tech blog
That’s all. Thanks.